Continual Release of Differentially Private Synthetic Data from Longitudinal Data Collections
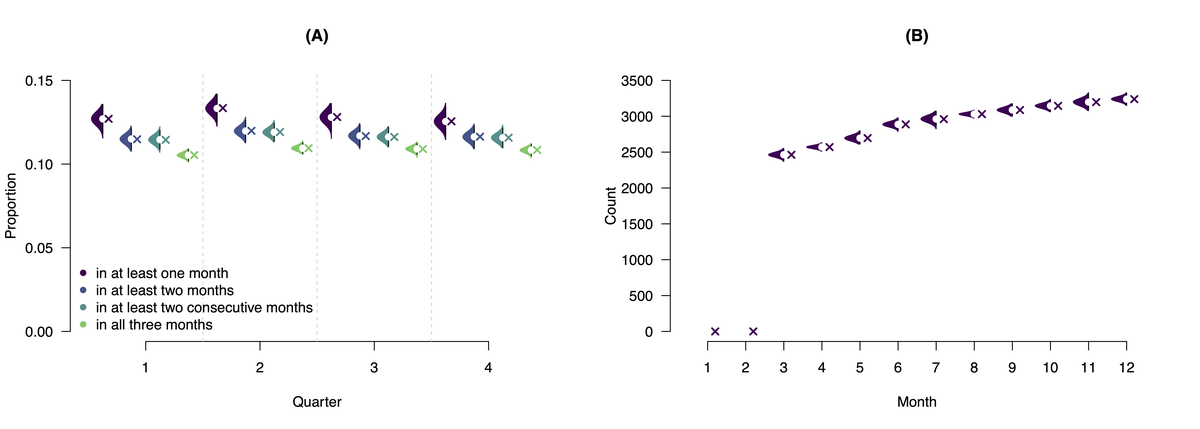 Panel (A): Proportions of SIPP Households in poverty per quarter in 2021. Panel (B): Count of SIPP Households in poverty for at least three months up to any given month in 2021. The density estimates show the empirical privacy noise distribution across 1000 repetitions of the experiments with privacy parameter rho = 0.005. Xs indicate values calculated from the SIPP data.
Panel (A): Proportions of SIPP Households in poverty per quarter in 2021. Panel (B): Count of SIPP Households in poverty for at least three months up to any given month in 2021. The density estimates show the empirical privacy noise distribution across 1000 repetitions of the experiments with privacy parameter rho = 0.005. Xs indicate values calculated from the SIPP data.
Abstract
Motivated by privacy concerns in long-term longitudinal studies in medical and social science research, we study the problem of continually releasing differentially private synthetic data from longitudinal data collections. We introduce a model where, in every time step, each individual reports a new data element, and the goal of the synthesizer is to incrementally update a synthetic dataset in a consistent way to capture a rich class of statistical properties. We give continual synthetic data generation algorithms that preserve two basic types of queries: fixed time window queries and cumulative time queries. We show nearly tight upper bounds on the error rates of these algorithms and demonstrate their empirical performance on realistically sized datasets from the U.S. Census Bureau’s Survey of Income and Program Participation.