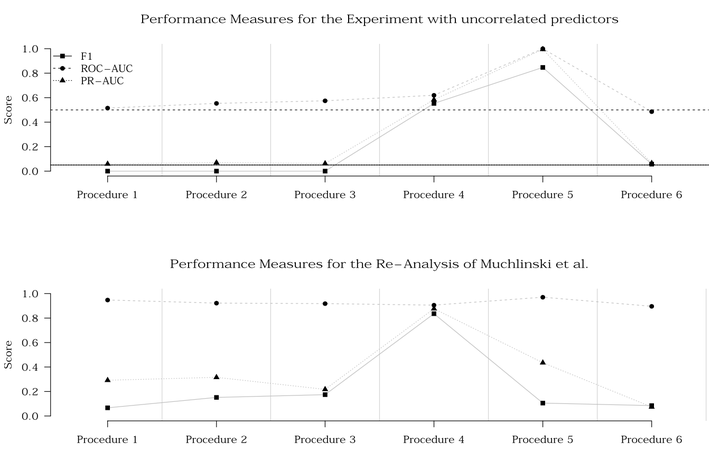
 Cross-Validation and Performance Measures. Top Panel: Experiment. Note that the lines for the true F1 score and the true PR-AUC score overlap. Lower Panel: Re-analysis of Muchlinski et al. (2016).
Cross-Validation and Performance Measures. Top Panel: Experiment. Note that the lines for the true F1 score and the true PR-AUC score overlap. Lower Panel: Re-analysis of Muchlinski et al. (2016).
Abstract
The introduction of new “machine learning” methods and terminology to political science complicates the interpretation of results. Even more so, when one term – like cross-validation – can mean very different things. We find different meanings of cross-validation in applied political science work. In the context of predictive modeling, cross-validation can be used to obtain an estimate of true error or as a procedure for model tuning. Using a single cross-validation procedure to obtain an estimate of the true error and for model tuning at the same time leads to serious misreporting of performance measures. We demonstrate the severe consequences of this problem with a series of experiments. We also observe this problematic usage of cross-validation in applied research. We look at Muchlinski et al. (2016) on the prediction of civil war onsets to illustrate how the problematic cross-validation can affect applied work. Applying cross-validation correctly, we are unable to reproduce their findings. We encourage researchers in predictive modeling to be especially mindful when applying cross-validation.
Marcel Neunhoeffer
Postdoctoral Researcher
I’m a quantitative social scientist with an interest in how new methods from computer sciences can be of use for social scientists. In particular, I’m interested in how to learn useful things from data without compromising privacy.